Распознайте фотографию, песню, привычку пользователя. С искусственным интеллектом это уже возможно. Но почему это важно и как это влияет на наш образ жизни?
Прежде чем ответить на этот вопрос, нам нужно сделать шаг назад и объяснить разницу между Artificial Intelligence (ИИ), Машинное обучение (МЛ) е Глубокое обучение (DL), термины, которые часто путают, но имеют очень точное значение.
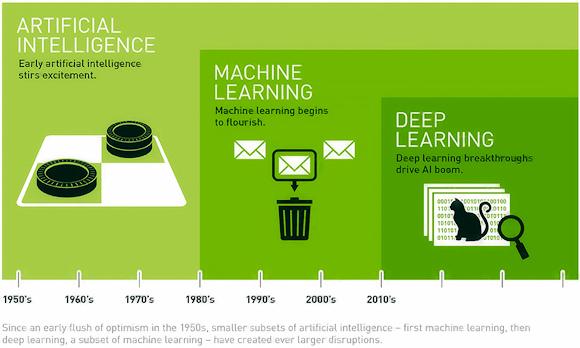
Для пояснения основной идеи воспользуемся изображением (открытием), взятым с сайта NVIDIA.
Из изображения ясно, что понятие ИИ — это общая концепция ML, которая, в свою очередь, является более общей концепцией DL. Но не только. Фактически, как мы видим, первые алгоритмы глубокое обучение они родились чуть более 10 лет назад, в отличие от искусственного интеллекта, который родился примерно в 50-х годах с первыми языками, такими как LISP и PROLOG, с целью имитировать возможности человеческого интеллекта.
Первые алгоритмы искусственного интеллекта ограничивались выполнением определенного возможного количества действий по определенной логике, заданной программистом (как в игре в шашки или шахматы).
Через обучение с помощью машиныИскусственный интеллект развивался посредством так называемых алгоритмов обучения с учителем и без учителя с целью создания математических моделей машинного обучения на основе большого количества входных данных, составляющих «опыт» искусственного интеллекта.
При обучении с учителем, чтобы создать модель, необходимо обучить ИИ, присваивая метку каждому элементу: например, если я хочу классифицировать фрукты, я сфотографирую множество разных яблок и присвою метку каждому элементу. модель «яблоко» как для груши, банана и т. д.
При обучении без учителя процесс будет обратным: необходимо будет создать модель, исходя из различных изображений фруктов, и модель должна будет извлечь метки в соответствии с характеристиками, общими для яблок, груш и бананов.
Модели обучение с помощью машины контролируемые уже используются антивирусами, спам-фильтрами, а также в сфере маркетинга, например, в продуктах, предлагаемых Amazon.
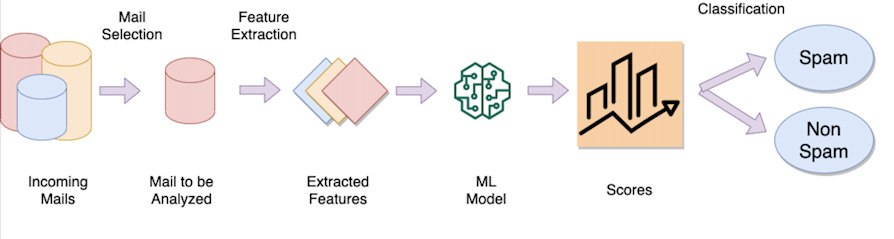
Пример спам-фильтра
Идея спам-фильтра электронной почты состоит в том, чтобы обучить модель, которая «обучается» на сотнях тысяч (если не миллионах) электронных писем, помечая каждое письмо как спам или законный. После обучения модели операция классификации включает в себя:
Извлечение особых характеристик (называемых признаками), таких как, например, слова текста, отправитель электронного письма, исходный IP-адрес и т. д.
Учитывайте «вес» для каждого извлеченного признака (например, если в тексте 1000 слов, некоторые из них могут быть более разборчивыми, чем другие, например, слово «виагра», «порно» и т. д. будет иметь вес, отличный от доброе утро, университеты и т. д.)
Выполнить математическую функцию, которая, принимая в качестве входных данных характеристики (слова, отправителя и т. д.) и их соответствующие веса, возвращает числовое значение.
Проверьте, превышает или ниже это значение определенный порог, чтобы определить, является ли электронное письмо законным или его следует считать спамом (классификация).
Искусственные нейроны
Приходите Глубокое обучение является филиалом обучение с помощью машины. Разница с обучение с помощью машины именно вычислительная сложность приводит к использованию огромных объемов данных с «многослойной» структурой обучения, состоящей из искусственных нейронных сетей. Чтобы понять эту концепцию, начнем с идеи репликации одного человеческого нейрона, как показано на рисунке ниже.
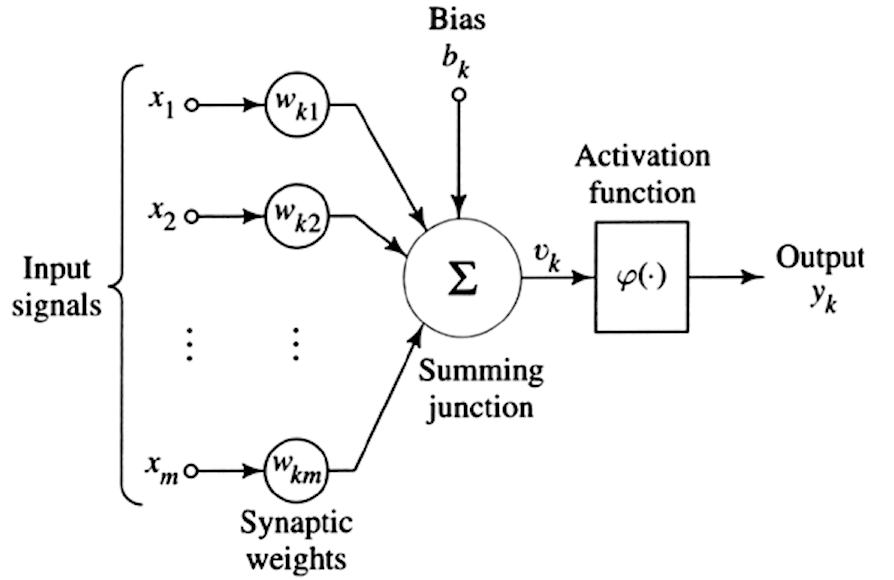
Как было замечено ранее для машинного обучения, у нас есть серия входных сигналов (слева от изображения), которым мы присваиваем разные веса (Wk), мы добавляем когнитивное «предвзятость» (bk), то есть своего рода искажение, и, наконец, мы применяем функция активации, то есть математическая функция, такая как сигмовидная функция, гиперболический тангенс, ReLU и т. д. который, принимая серию взвешенных входных данных и принимая во внимание смещение, возвращает результат (yk).
Это единственный искусственный нейрон. Чтобы создать нейронную сеть, выходы одного нейрона соединяются с одним из входов следующего нейрона, образуя плотную сеть соединений, как показано на рисунке ниже, которая представляет собой фактическую сеть. Глубокая нейронная сеть.
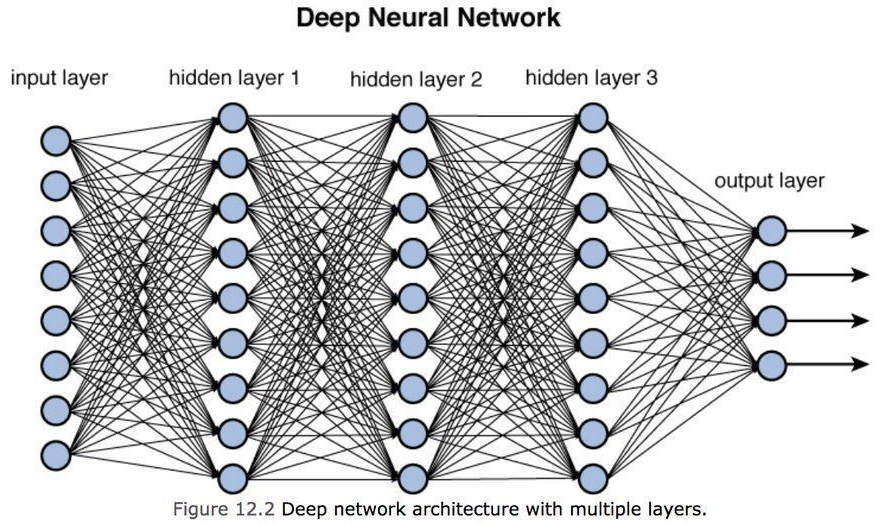
Глубокое обучение
Как видно на рисунке выше, у нас есть набор входных данных для нейронной сети (входной уровень), затем промежуточные уровни, называемые скрытыми слоями, которые представляют «слои» модели, и, наконец, выходной уровень, способный различать (или распознавать) один объект над другим. Мы можем рассматривать каждый скрытый уровень как способность к обучению: чем больше количество промежуточных слоев (т. е. чем глубже модель), тем точнее понимание, но также и более сложные вычисления, которые необходимо выполнить.
Обратите внимание, что выходной слой представляет собой набор выходных значений с определенной степенью вероятности, например 95% яблоко, 4,9% груша и 0,1% банан и так далее.
Давайте представим себе модель DL в области компьютерное зрение: первый слой способен распознавать края объекта, второй слой, начиная с краев, может распознавать формы, третий слой, начиная с фигур, может распознавать сложные объекты, состоящие из нескольких фигур, четвертый слой, начиная со сложных фигур, может узнавать детали и так далее. При определении модели не существует точного количества скрытый слой, но ограничение накладывается мощностью, необходимой для обучения модели за определенное время.
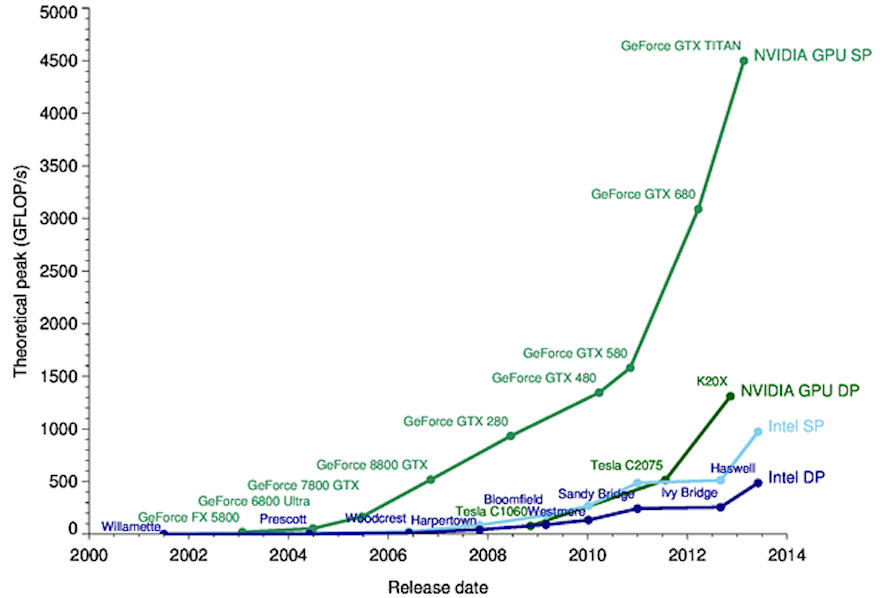
Не вдаваясь в подробности, обучение нейронной сети имеет своей целью вычисление всех весов и смещений, которые должны быть применены ко всем отдельным нейронам, присутствующим в модели: поэтому очевидно, как сложность увеличивается экспоненциально по мере промежуточного уровня. увеличение слоев (скрытые слои). По этой причине процессоры видеокарт (GPU) используются уже много лет. обучение: эти карты подходят для более требовательных рабочих нагрузок, поскольку, в отличие от процессоров, они способны выполнять тысячи операций параллельно с использованием архитектуры SIMD (одна инструкция для нескольких данных), а также современных технологий, таких как Тензорное ядро которые позволяют выполнять матричные операции аппаратно.
Приложения глубокого обучения
Обрабатывая огромные объемы данных, эти модели обладают высокой устойчивостью к ошибкам и шуму, несмотря на неполные или неточные данные. Поэтому сейчас они обеспечивают фундаментальную поддержку во всех областях науки. Давайте посмотрим на некоторые из них.
Классификация изображений и безопасность
В случае преступлений это позволяет распознавать лица, начиная с изображения, снятого камерой наблюдения, и сравнивая его с базой данных из миллионов лиц: эта операция, если она выполняется людьми вручную, может занять дни, если не месяцы или даже годы. Кроме того, посредством реконструкции изображений некоторые модели позволяют раскрашивать недостающие части изображений с точностью, близкой к 100% исходного цвета.
Обработка естественного языка
Способность компьютера понимать письменный и устный текст так же, как это делают люди. Среди наиболее известных систем — Alexa и Siri, способные не только понимать, но и отвечать на вопросы различного характера.
Другие модели способны на это. анализ настроений, всегда используя системы извлечения и мнения из текста или слов.
Медицинские диагнозы
В медицинской сфере эти модели теперь используются для постановки диагноза, включая анализ компьютерной томографии или МРТ. Результаты, которые в выходном слое имеют достоверность 90-95%, в некоторых случаях позволяют прогнозировать терапию пациента без вмешательства человека. Способные работать 24 часа в сутки, каждый день, они также могут оказывать поддержку на этапе сортировки пациентов, значительно сокращая время ожидания в отделении неотложной помощи.
Автономное руководство
Системы беспилотного вождения требуют постоянного мониторинга в режиме реального времени. К более совершенным моделям относятся транспортные средства, способные управлять любой дорожной ситуацией независимо от водителя, присутствие которого на борту не предусмотрено, предусматривая присутствие только перевозимых пассажиров.
Прогнозы и профилирование
Модели финансового глубокого обучения позволяют нам строить гипотезы о будущих тенденциях рынка или знать риск неплатежеспособности организации более точно, чем люди могут это сделать сегодня с помощью интервью, исследований, анкет и ручных расчетов.
Эти модели, используемые в маркетинге, позволяют нам понять вкусы людей и предлагать новые продукты, например, на основе ассоциаций, возникающих с другими пользователями, имеющими аналогичную историю покупок.
Адаптивная эволюция
На основе загруженного «опыта» модель способна адаптироваться к ситуациям, возникающим в окружающей среде или в результате действий пользователя. Адаптивные алгоритмы заставляют всю нейронную сеть обновляться на основе новых взаимодействий с моделью. Например, давайте представим, как YouTube предлагает видео определенной темы в зависимости от периода, адаптируясь день за днём и месяц за месяцем к нашим новым личным вкусам и интересам.
Наконец, Глубокое обучение Это область исследований, которая по-прежнему быстро расширяется. Университеты также обновляют свои учебные программы по этому предмету, который по-прежнему требует прочной математической основы.
Преимущества, которые дает применение ДО в промышленности, исследованиях, здравоохранении и повседневной жизни, несомненны.
Однако нельзя забывать, что это должно оказывать поддержку человеку и что лишь в некоторых ограниченных и весьма специфических случаях оно может заменить человека. На сегодняшний день фактически не существует моделей «общего назначения», способных решить задачи любого типа.
Другим аспектом является использование этих моделей в незаконных целях, например для создания видеороликов. DeepFake (см. статью), то есть методы, используемые для наложения других изображений и видео на оригинальные изображения или видео с целью создания фейковых новостей, мошенничества или порномести.
Еще один незаконный способ использования этих моделей — создание серии методов, направленных на компрометацию компьютерной системы, таких как состязательное машинное обучение. С помощью таких методов можно вызвать неправильную классификацию модели (и, таким образом, привести к неправильному выбору модели), получить информацию об используемом наборе данных (что создает проблемы конфиденциальности) или клонировать модель (вызывает проблемы с авторскими правами).
Ссылки
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-int...
https://it.wikipedia.org/wiki/Lisp
https://it.wikipedia.org/wiki/Prolog
https://it.wikipedia.org/wiki/Apprendimento_supervisionato
https://www.enjoyalgorithms.com/blog/email-spam-and-non-spam-filtering-u...
https://foresta.sisef.org/contents/?id=efor0349-0030098
https://towardsdatascience.com/training-deep-neural-networks-9fdb1964b964
https://hemprasad.wordpress.com/2013/07/18/cpu-vs-gpu-performance/
https://it.wikipedia.org/wiki/Analisi_del_sentiment
https://www.ai4business.it/intelligenza-artificiale/auto-a-guida-autonom...
https://www.linkedin.com/posts/andrea-piras-3a40554b_deepfake-leonardodi...










